Disclaimer: This is an AI generated summary of our report, please contact us directly for further information.
In the high-stakes domain of IT security and reverse engineering, identifying whether two binary functions stem from the same source is a critical challenge. Code obfuscation, varying compiler optimizations, and cross-platform dependencies often mask the underlying logic, making manual analysis inefficient.
Our project focused on maximizing the effectiveness of Binary Function Similarity Detection (BFSD) by evaluating Siamese Neural Network architectures, leveraging automated hyperparameter tuning, and introducing a novel “Transferhead” approach.
The Architecture: Siamese Neural Networks
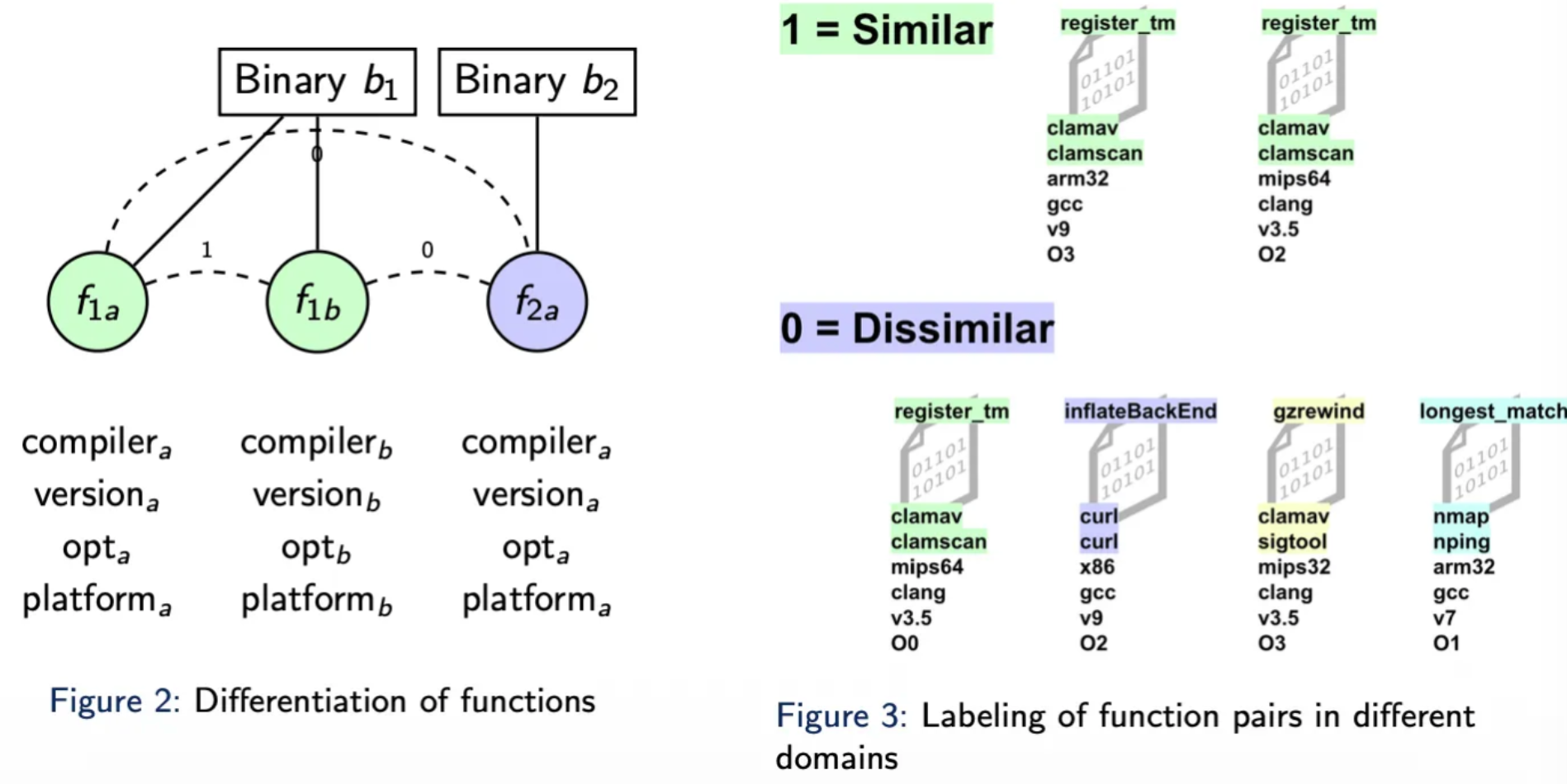
To solve for similarity, we utilized Siamese Architectures — networks that process two separate inputs through shared weights to produce comparable embeddings. We tested two primary labeling strategies:
Binary Labels: Predicting a simple 0 (dissimilar) or 1 (similar).
Continuous Labels: Predicting a similarity score in the range of [0,1] based on cosine similarity.
Precision Engineering via Autotuning
To ensure our solutions were not just “low effectiveness” experiments, we integrated Optuna for hyperparameter autotuning. This allowed us to mathematically optimize our objective values — such as maximizing accuracy or minimizing Mean Squared Error (MSE) — by systematically exploring parameter spaces for learning rates, hidden layer sizes, and loss margins.

Key Findings and Strategic Pivots
Our initial experiments provided several high-information takeaways that redirected our approach:
Attention Isn’t a Silver Bullet: For binary labels, the inclusion of attention layers performed mediocre. Architectures without attention were generally smaller yet achieved superior performance.
The LSTM Staticity Problem: While LSTMs were introduced to catch bidirectional features, they proved too static for this specific task.
Machine Learning Regressors: Traditional ML methods like Gradient Boosting showed competitive results, with a Test MSE as low as 0.0386, suggesting they remain viable for specific BFSD applications.
The Final Approach
Our most impactful contribution is our Siamese BERT-Encoder CNN-Transferhead. This architecture moves beyond baseline performance by treating the problem as a sophisticated feature extraction task:

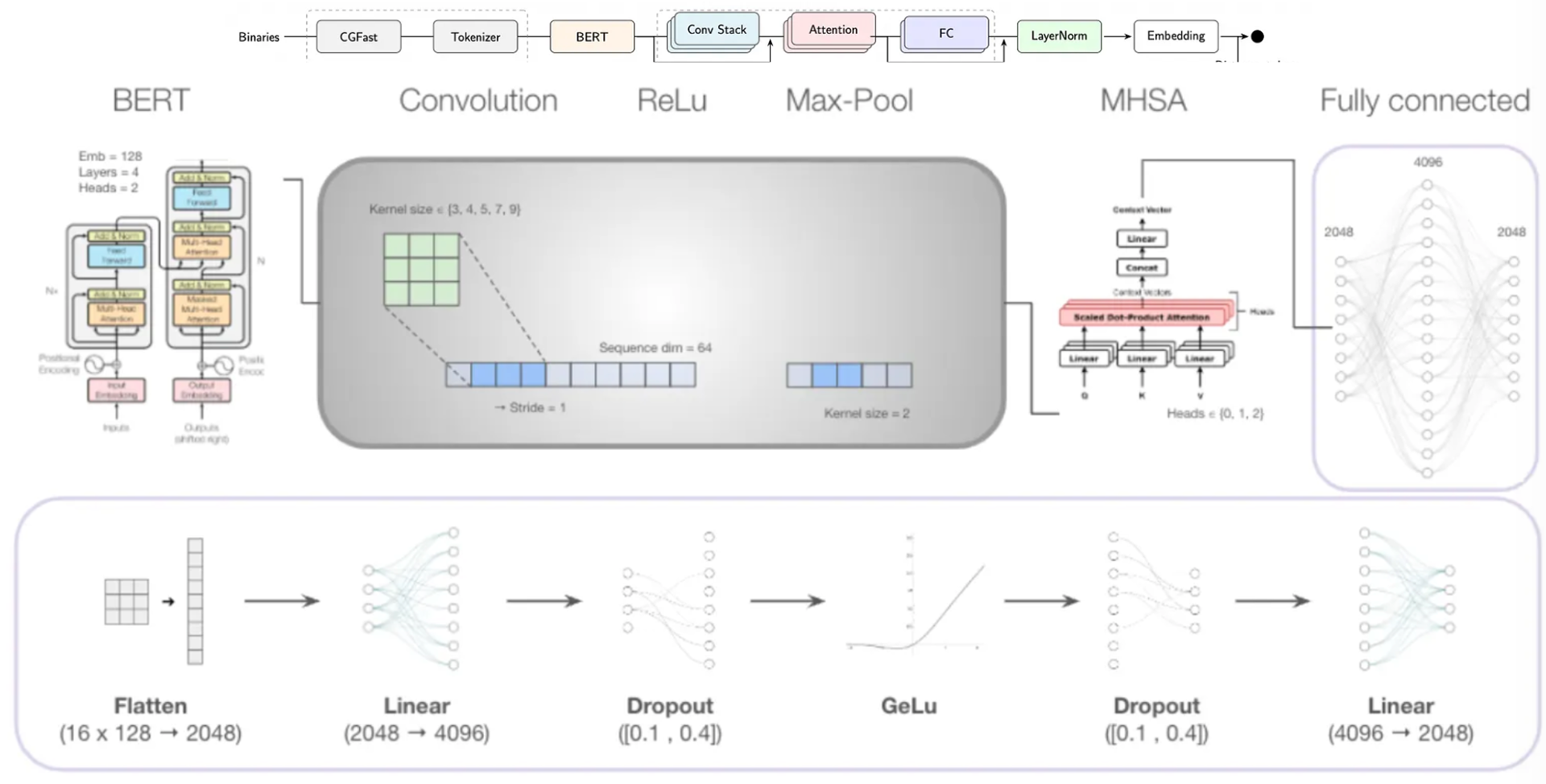
Encoder: A frozen BERT model pretrained on assembly tokens provides foundational features.
Transfer Head: We appended a trainable architecture consisting of a Convolution Stack (1–4 layers), Multi-Head Self-Attention (MHSA), and Fully Connected layers.
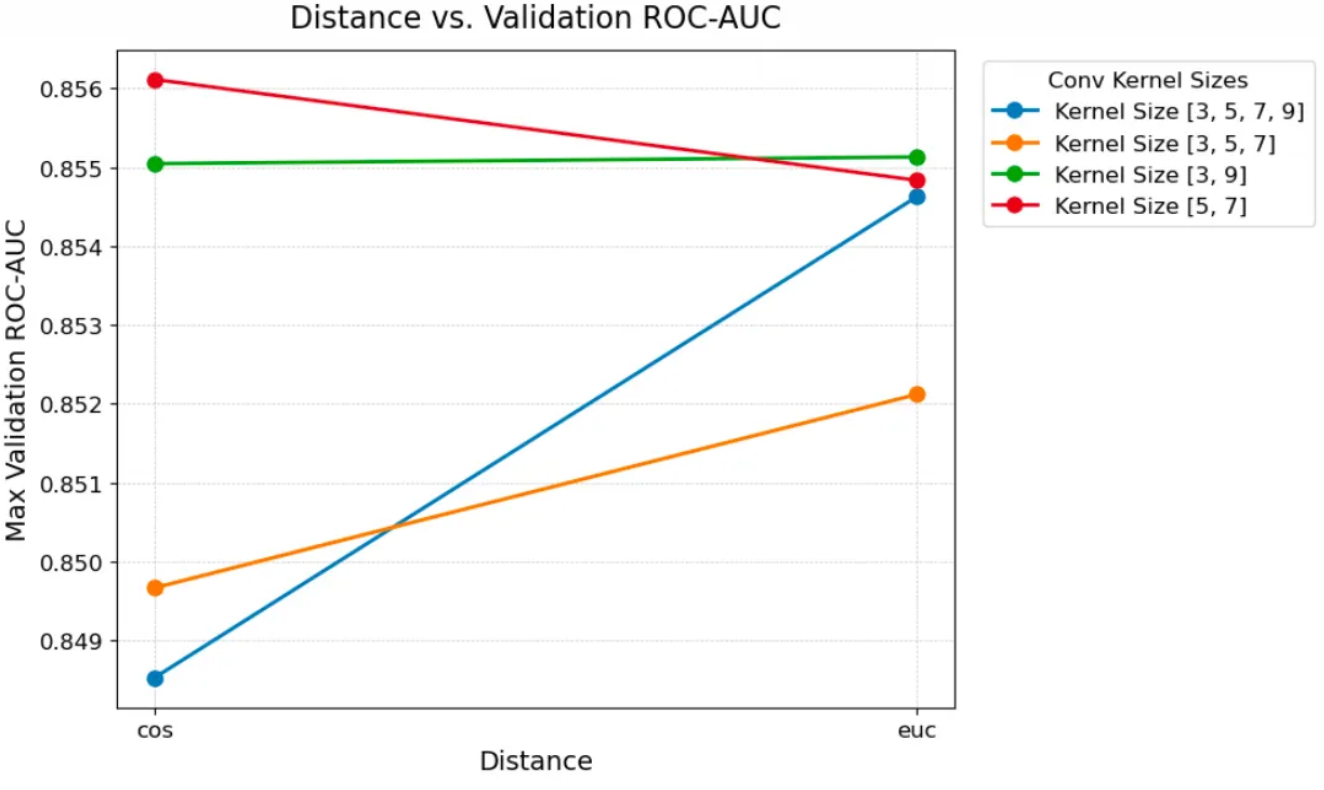
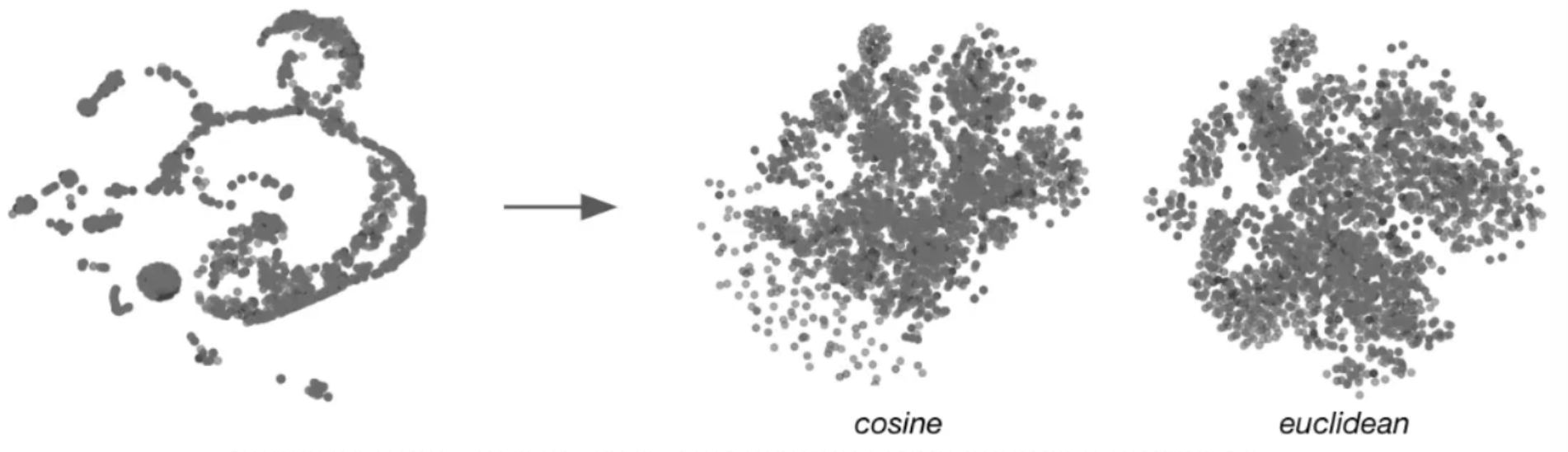
Refined Distance Metrics: We discovered that Scaled Euclidean Distancegeneralizes better and reduces overfitting compared to standard cosine distance.
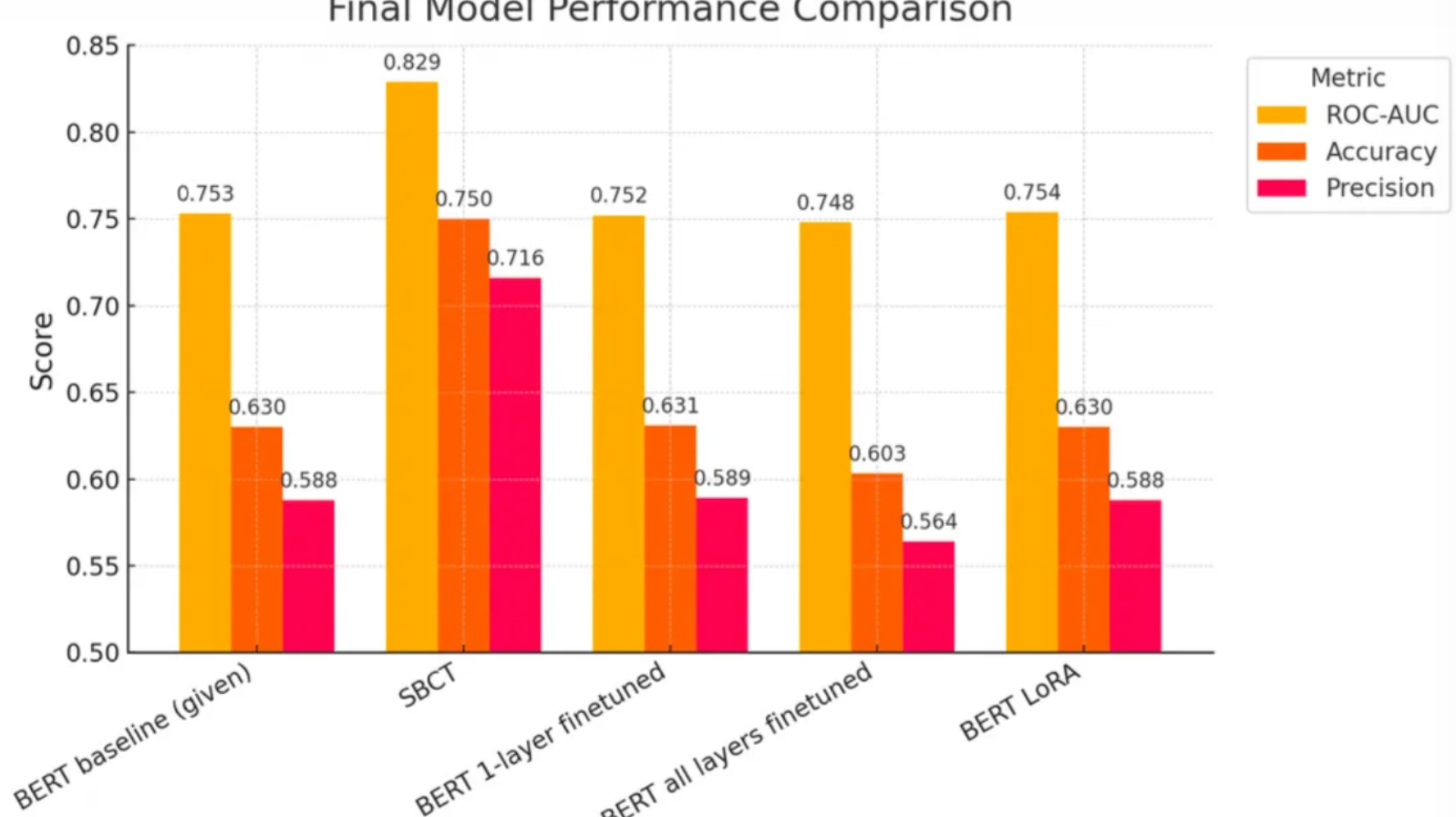
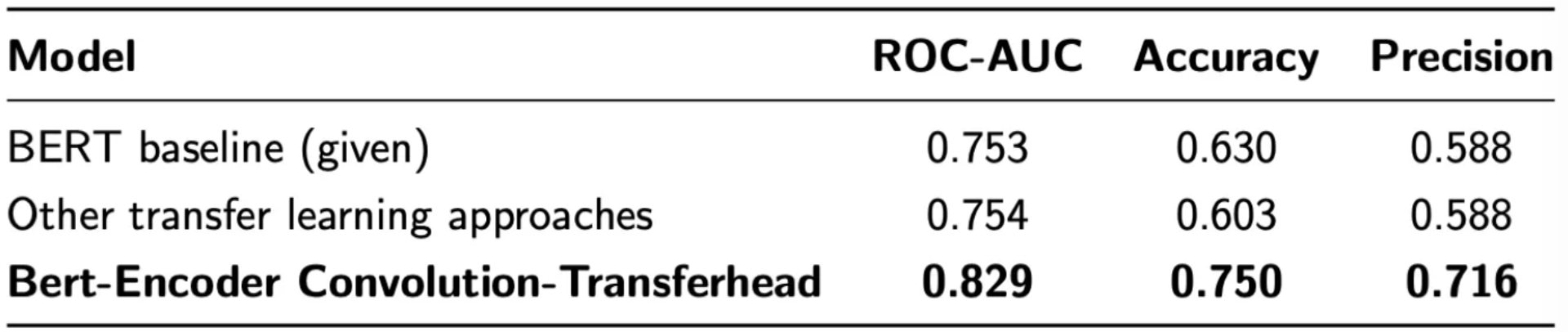
Quantitative Impact
The SBCT model delivered an undeniable improvement over the baseline, in particular in precision:
Conclusion: Scaling for Impact
Capturing semantic features in heterogeneous domains requires more than just raw data; it requires an architecture capable of learning structural patterns. By utilizing a Siamese BERT-Encoder with a specialized Convolution-Transferhead, we raised the performance ceiling for binary similarity from ~76% to ~86%. This high-precision approach provides a robust foundation for next-generation security tools.